QwQ-32B: Reshaping Reasoning with Scalable Reinforcement Learning


Try QwQ-32B in ChatHub
The realm of artificial intelligence continues to evolve rapidly, and within this transformative era, emerging innovations challenge the boundaries of what machines can achieve in reasoning and problem-solving. Enter QwQ, the groundbreaking reasoning model from the Qwen series. Designed to redefine how AI models reason through complex tasks, make decisions, and solve problems, QwQ outshines conventional instruction-tuned models with its ability to think critically and adapt dynamically across complex use cases.
In this article, we’ll explore QwQ-32B, the medium-sized member of the QwQ family, and demonstrate how it achieves state-of-the-art reasoning performance through innovative training techniques, particularly Reinforcement Learning (RL). We’ll discuss the model’s unique architecture, performance benchmarks, and how it compares to other leading language models, unlocking its potential in shaping the future of artificial general intelligence (AGI).
What is QwQ-32B?
QwQ-32B is a cutting-edge reasoning model equipped with 32.5 billion parameters, specifically designed to tackle advanced reasoning tasks in domains such as mathematics, coding, and general problem-solving. Unlike models that rely purely on instruction tuning, QwQ achieves exceptional performance in challenging downstream tasks, largely through its capacity for critical thinking and its innovative reinforcement learning methodologies.
Key Features of QwQ-32B:
- Type: Causal Language Model (CLM)
- Training Stages: Pretraining & Post-Training (including Supervised Fine-tuning and RL)
- Architecture:
- Transformers enhanced with RoPE, SwiGLU, RMSNorm, and Attention QKV bias.
- Context Length: Supports up to 131,072 tokens, making it ideal for tasks requiring expansive context.
- Parameters:
- Total: 32.5 billion
- Non-Embedding: 31.0 billion
- Dimensions: 64 layers with 40 Query heads and 8 Key/Value heads (GQA).
From these robust architectural details, it’s clear that QwQ-32B is built for performance. The model’s unique combination of structural innovations allows it to handle large-scale reasoning tasks efficiently, rivaling models with significantly larger parameter counts.
Solving Hard Problems: QwQ-32B vs. Competitors
QwQ-32B achieves competitive reasoning performance on multiple benchmarks, often rivaling or surpassing state-of-the-art models such as DeepSeek-R1, o1-mini, and others. This is no small feat, as DeepSeek-R1, the reigning leader in reasoning tasks, boasts an enormous parameter count of 671 billion (with 37 billion activated), significantly surpassing QwQ in size. QwQ’s efficiency and problem-solving abilities highlight the effectiveness of reinforcement learning when scaled for critical thinking and general intelligence.
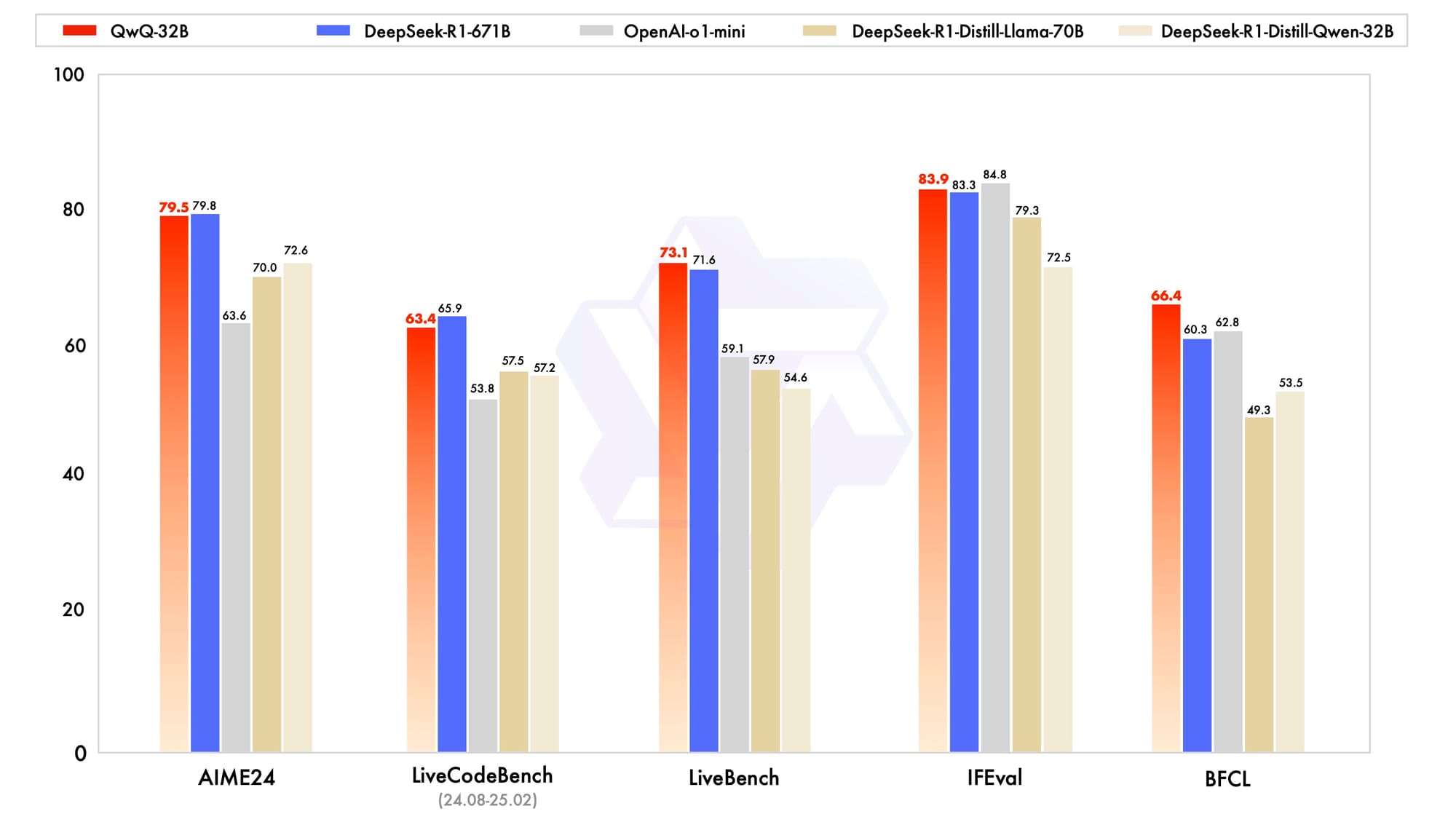
Testing Grounds:
QwQ-32B is rigorously evaluated across complex domains including:
- Mathematical Reasoning: The ability to solve high-complexity problems with precise solutions.
- Coding Proficiency: Generating executable code and achieving success in passing sophisticated test cases.
- General Problem-Solving: Tackling diverse tasks beyond specific niches like math and code.
Notable Standout Features:
QwQ leverages innovative reward systems to fine-tune its reasoning capabilities:
- Math-Verifier Accuracy: Ensures solutions to mathematical problems are correct.
- Code Execution Server: Assesses whether code generation successfully passes prescribed test requirements.
These methodologies produce measurable improvements over time, setting new standards for the incremental training of reasoning models.
Why Reinforcement Learning Fuels QwQ-32B’s Success
Reinforcement Learning (RL) has become a cornerstone of advanced AI development. Unlike traditional pretraining and supervised fine-tuning, RL enables adaptive learning via feedback loops. For QwQ-32B, RL proves instrumental in scaling intelligence beyond current benchmarks.
RL Implementation in QwQ-32B:
- Cold-Start Checkpoint: QwQ-32B begins its RL journey with a cold-start checkpoint specifically optimized for math and coding.
- Outcome-Based Rewards:
- Math tasks focus on verifier-based accuracy (ensuring correctness).
- Coding proficiency evaluates whether the AI-generated code successfully passes structured test cases.
- Second RL Phase for General Capabilities:
- Includes general-purpose reward models and rule-based verifiers.
- Results in enhanced capabilities such as instruction following, human alignment, and improved agent-based performance.
Advantages of RL in QwQ-32B:
- Scalability: RL ensures continuous performance improvements, even for highly specialized tasks such as mathematical theorem solving.
- Efficiency: By focusing on outcomes, RL avoids the inefficiencies of traditional supervised reward models.
- Diverse Training Outcomes: Even with a relatively small number of training steps in later RL stages, general performance improvements are observed across various capabilities.
The Impact of QwQ-32B: A Leap in AI Reasoning
QwQ-32B not only competes with larger models like DeepSeek-R1 but also introduces critical advancements in reasoning and adaptability. By integrating agent-related capabilities, QwQ empowers the model to think critically, utilize external tools, and adapt its reasoning in response to environmental feedback—an essential step on the path to achieving AGI.
Comparison with DeepSeek-R1:
- Parameter Difference: While DeepSeek-R1 relies on 671 billion parameters for its success, QwQ-32B delivers comparable performance with only 32.5 billion parameters.
- Efficiency: QwQ-32B's ability to outperform certain DeepSeek benchmarks highlights the success of an optimal architecture and RL-based training rather than sheer size.
- Open Access: Unlike proprietary models, QwQ-32B is open-weight and available on platforms such as Hugging Face and ModelScope under the Apache 2.0 license.
Areas of Application:
- AI-Assisted Problem-Solving:
- Math and technical problem-solving at an unparalleled efficiency.
- Tool Utilization by Agents:
- Adapts to real-world tasks, using external feedback for reasoning.
- Large Context Understanding:
- Handles up to 131,072 tokens, allowing comprehensive insights into tasks requiring expansive input context.
Open Access to QwQ-32B: Where to Explore
QwQ-32B is offered with open-weight accessibility under the Apache 2.0 license, available through prominent platforms:
Additionally, QwQ-32B can be experimented with via Qwen Chat, an interactive environment that showcases its reasoning and agent-based problem-solving.
The Future of AI Reasoning with QwQ
QwQ-32B exemplifies how modern models are reshaping the landscape of artificial intelligence reasoning. Achieving competitive performance against giants like DeepSeek-R1 shows that innovation in training methodologies (e.g., RL) can overcome parameter limitations. This model not only advances us towards more capable reasoning systems but also signals significant progress in building the foundation for artificial general intelligence.
By embracing scalability, efficiency, and adaptability, QwQ establishes itself as an innovation that can address the increasing complexity of future AI challenges.



